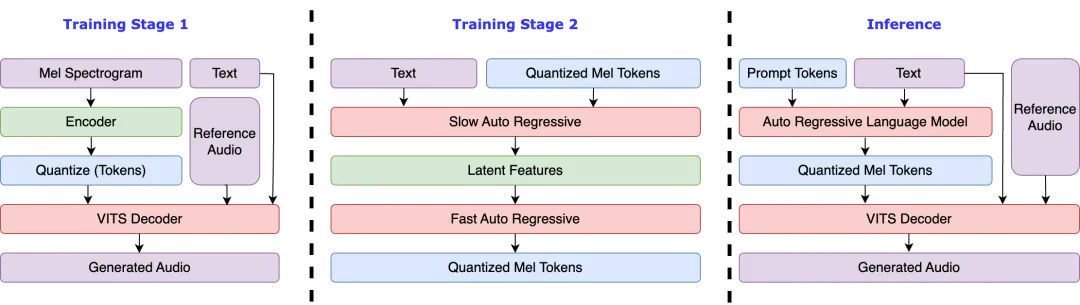
VoxCPM2 深度实战:当开源 TTS 突破「tokenizer 诅咒」——从Tokenizer-Free 架构到本地 CPU/GPU 部署的完全指南(2026)
2026-06-09 14:50:53 +0800 CST view 131
MOSS-TTS-Nano:0.1B参数纯CPU实时语音生成与克隆,MacBook Air单核就能跑
2026-04-20 22:53:28 +0800 CST view 885
OmniVoice Studio:5k Star开源声音克隆工具,646种语言,无GPU也能跑
2026-05-28 20:50:27 +0800 CST view 260
NeuTTS Air:0.5B参数超拟真语音合成,3秒音频克隆你的声音
2026-04-28 12:43:51 +0800 CST view 302
OmniVoice 深度实战:当小米 AI 实验室把 600 种语言的 TTS 引擎彻底开源——从零样本语音克隆到单阶段 NAR 架构的生产级完全指南(2026)
2026-06-11 11:18:37 +0800 CST view 160
OmniVoice 深度实战:当小米 k2-fsa 团队用扩散语言模型重塑语音合成——从零样本克隆到 600 语言高保真 TTS 的生产级完全指南(2026)
2026-06-15 14:21:23 +0800 CST view 97
VibeVoice 深度解析:微软 45K Star 开源语音 AI,重新定义长音频处理范式
2026-04-29 11:11:12 +0800 CST view 274
NVIDIA PersonaPlex 全双工语音 AI 深度解析:从 Moshi 架构到实时对话的工程实践
2026-04-19 14:16:23 +0800 CST view 541
VibeVoice 深度实战:当微软用 60 分钟长音频打破语音 AI 的「时长诅咒」——从实时语音合成到 Hugging Face 生态集成的生产级完全指南(2026)
2026-06-17 00:25:12 +0800 CST view 16
VibeVoice 深度解析:微软开源语音AI全家桶——从7.5Hz超低帧率到Next-Token Diffusion的技术革命
2026-05-17 18:16:11 +0800 CST view 248
VibeVoice 深度实战:从 7.5Hz 超低帧率到 Next-token Diffusion——2026 年微软开源语音 AI 模型家族的架构完全指南
2026-05-23 22:32:58 +0800 CST view 207
VibeVoice 深度解析:微软开源语音 AI 全家桶,90 分钟长语音合成 + 60 分钟语音识别
2026-05-13 22:42:48 +0800 CST view 301
VibeVoice 深度实战:微软开源的 33K Star 语音AI全家桶——从架构设计到生产部署的全链路解析
2026-05-06 13:01:56 +0800 CST view 697
VibeVoice 深度解析:微软如何用 7.5Hz 连续语音分词器重新定义语音 AI 的边界
2026-04-18 07:48:59 +0800 CST view 334
VibeVoice 深度实战:当 TTS 遇见扩散模型与 LLM——从 3200 倍压缩到 90 分钟多人对话的生产级完全指南(2026)
2026-06-16 02:16:25 +0800 CST view 37
PersonaPlex 深度解析:当 NVIDIA 让全双工语音对话进入「角色扮演」时代
2026-04-09 11:32:36 +0800 CST view 613
微软 VibeVoice 深度实战:从 7.5Hz 超低帧率到 90 分钟长音频合成——下一代语音 AI 的架构革命与生产级实践
2026-05-23 01:45:11 +0800 CST view 266
VoxCPM2:无分词 Tokenizer-Free 语音合成——从架构革命到工程落地的完整指南
2026-04-19 14:46:06 +0800 CST view 651
Insanely Fast Whisper 深度解析:比原版快 10 倍的语音转文字引擎——从原理到生产级部署的完整实战
2026-04-29 16:24:38 +0800 CST view 298
VibeVoice 深度解析:当微软把60分钟语音识别压缩进一颗 GPU
2026-04-11 08:44:54 +0800 CST view 515
VibeVoice 深度解析:微软如何用 7.5Hz 超低帧率暴力破解 90 分钟长语音合成——开源语音 AI 的技术革命
2026-05-10 23:20:20 +0800 CST view 415
FishSpeech是一个全新的文本到语音(TTS)解决方案,采用变分自编码器、声码器和生成对抗网络等先进技术,提供高质量、自然的语音合成
2024-11-19 04:18:33 +0800 CST view 2340