TileLang + TileKernels 深度解析:DeepSeek 如何用 Python 写出让 GPU 逼近理论性能上限的 GPU 内核
2026-04-28 10:55:20 +0800 CST view 334
Sidecarless服务网格深度解析:Rust+eBPF如何引爆2026年云原生性能革命
2026-05-16 08:17:15 +0800 CST view 299
template-vue3-gin-fullstack:Vue3+Go Gin前后端分离全栈项目模板,开箱即用
2026-05-09 10:27:01 +0800 CST view 278
Kimi K2.6 开源深度测评:国产模型首次登顶全球代码榜首,开发者必须知道的那些事
2026-04-28 15:51:45 +0800 CST view 757
MusaCoder 深度实战:当国产GPU遇见AI驱动的Kernel生成——从PyTorch到CUDA/MUSA原生算子的全栈训练完全指南(2026)
2026-06-16 06:47:47 +0800 CST view 103
DuckLake v1.0 深度解析:DuckDB 团队如何用关系型数据库颠覆数据湖架构——926 倍性能背后的湖仓一体新范式
2026-05-09 13:14:28 +0800 CST view 668
RAG 2026 生产级工程化完全指南:从朴素检索到 Agentic RAG 的架构演进与性能优化实战
2026-05-23 03:16:51 +0800 CST view 224
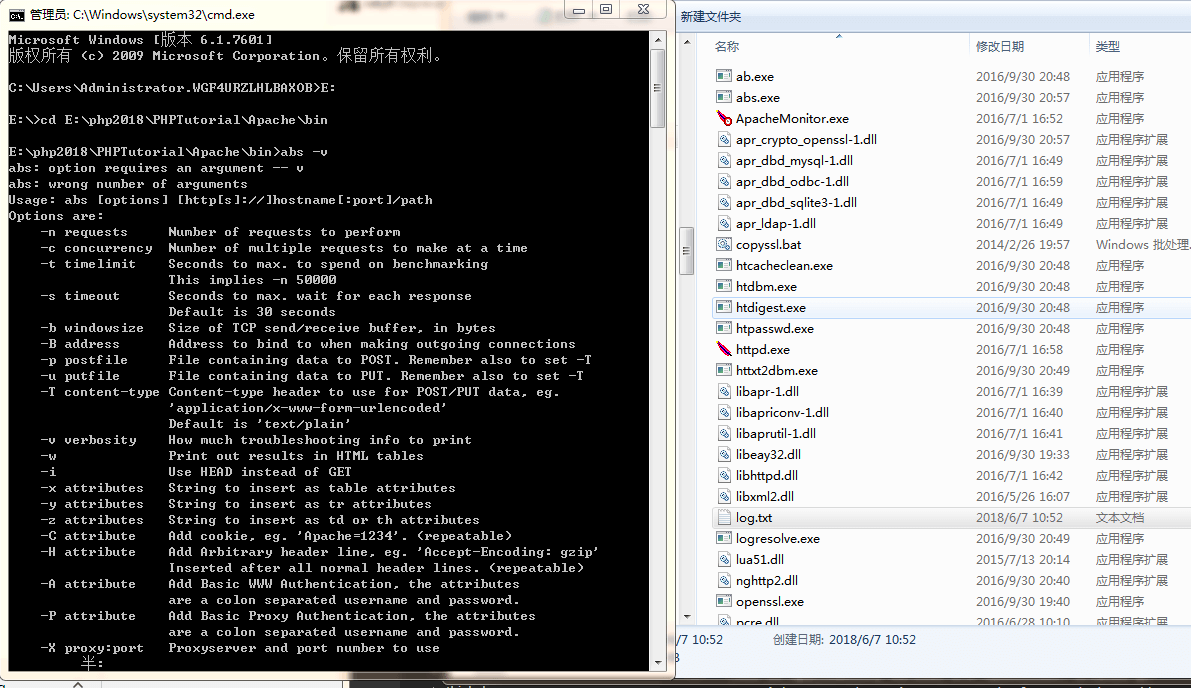
apache自带的ab(http)与abs(https)压测工具用法详解
2024-11-19 01:53:49 +0800 CST view 8370
Polars 深度实战:碾压 Pandas 的 Rust 极速 DataFrame 引擎——从 Apache Arrow 内存模型到 Lazy Execution 的完全指南(2026)
2026-06-02 16:24:32 +0800 CST view 208
向量数据库深度实战:PGVector vs Qdrant vs Milvus vs Chroma——从嵌入式到分布式的生产级完全指南(2026)
2026-06-16 22:52:56 +0800 CST view 90
MarkItDown 深度实战:当微软用 Python 把「文档地狱」变成 Markdown 乐园——从多格式解析到 RAG 知识库落地的生产级完全指南(2026)
2026-06-16 23:52:04 +0800 CST view 71

SANA-WM 深度解析:2.6B 参数开源世界模型如何颠覆视频生成——从扩散Transformer到1分钟720p实时渲染的完整技术架构
2026-05-16 21:15:15 +0800 CST view 822
Helidon 4.4 深度解析:当 Oracle 把 LangChain4j AI Agent 能力直接内建进 Java 微服务框架
2026-04-11 11:26:05 +0800 CST view 692
CloakBrowser深度解析:源代码级指纹修补如何让AI爬虫彻底绕过所有Bot检测
2026-05-17 02:15:27 +0800 CST view 485
TriAttention深度解析:用三角函数革命性压缩KV Cache,让长推理从「显存地狱」中脱困
2026-05-17 04:14:18 +0800 CST view 277
vLLM 深度实战:从 PagedAttention 到 Speculative Decoding——2026年大模型推理引擎内核架构完全指南
2026-05-23 18:44:14 +0800 CST view 311
【重制版】TriAttention深度解析:三角函数如何让长推理从显存地狱中脱困
2026-05-17 04:14:33 +0800 CST view 255
CC Switch:45K Star 的 AI 大模型万能遥控器,让 100+模型说同一种语言
2026-05-01 15:33:28 +0800 CST view 1132
MonkeyCode:免费开云端开发环境,手机也能写代码提GitHub,长亭科技推出的在线AI开发平台
2026-06-17 12:58:35 +0800 CST view 54
PyCharm 2026.1 调试器架构大重构:debugpy 上位、PEP 669 原生支持、asyncio 调试不再崩溃——一次迟到五年的工程救赎
2026-04-12 06:24:24 +0800 CST view 513
LLM推理引擎全栈优化实战:从PagedAttention到投机解码,榨干GPU的每一滴算力
2026-05-17 10:21:56 +0800 CST view 351
万字深度:PagedAttention、连续批处理与投机解码——LLM推理优化七层实战
2026-05-17 10:22:13 +0800 CST view 306
Apache Doris 4.1 深度拆解:当实时数仓长出 AI 大脑——从向量检索到统一数据底座的全链路技术实战
2026-05-02 10:33:28 +0800 CST view 376