2026 CSS 新特性深度解析:从 Popper.js 到原生锚点定位,前端工具链的终极进化
2026-04-19 22:45:35 +0800 CST view 648
reqres 深度解析:2.6K SLoC 的 Rust 异步 HTTP 客户端,如何重新定义网络请求的极简范式
2026-04-30 13:54:33 +0800 CST view 562
Shopify GraphQL Cardinal 深度解析:广度优先执行引擎如何让大型列表查询提速 15 倍
2026-05-10 19:53:54 +0800 CST view 534
2026 大模型推理框架终极对决:vLLM 0.5 vs TGI 2.0 vs TensorRT-LLM 1.8 vs DeepSpeed-MII 0.9——从架构原理到生产级部署的完全指南
2026-06-16 23:24:43 +0800 CST view 285
Vue3 实现页面上下滑动方案
2025-06-28 17:07:57 +0800 CST view 1689
Go 语言 2026 深度拆解:当云原生之王迎来 SIMD、分代 GC 与 AI 原生的「三重觉醒」
2026-07-18 07:42:42 +0800 CST view 134
Bun 深度解析:从 Zig 到 Rust 的史诗级迁移——JavaScript 运行时性能革命的工程全景
2026-06-30 06:44:20 +0800 CST view 466
Rust重写一切:2026年AI基础设施全面Rust化的技术浪潮——从推理引擎到向量数据库,从编译器到运行时的深度解析
2026-07-05 22:44:34 +0800 CST view 505
Drizzle ORM + Bun 性能革命:当 TypeScript 生态终于在数据库层跑出比 Go 更低的延迟
2026-07-11 17:15:17 +0800 CST view 192
React Compiler Rust 深度实战:当 Meta 用 Rust 重写前端编译核心——从自动记忆化原理到 NAPI 绑定的生产级完全指南(2026)
2026-06-17 00:55:41 +0800 CST view 419
HTML 解析器性能深度横评:从 Lexbor 的 SIMD 优化到 BeautifulSoup 的易用性权衡——2026 年爬虫基础设施选型指南
2026-06-30 07:15:57 +0800 CST view 304
Zig 0.14 深度实战:从 comptime 元编程到 C 互操作——系统编程新范式的生产级完全指南
2026-05-23 10:50:36 +0800 CST view 474
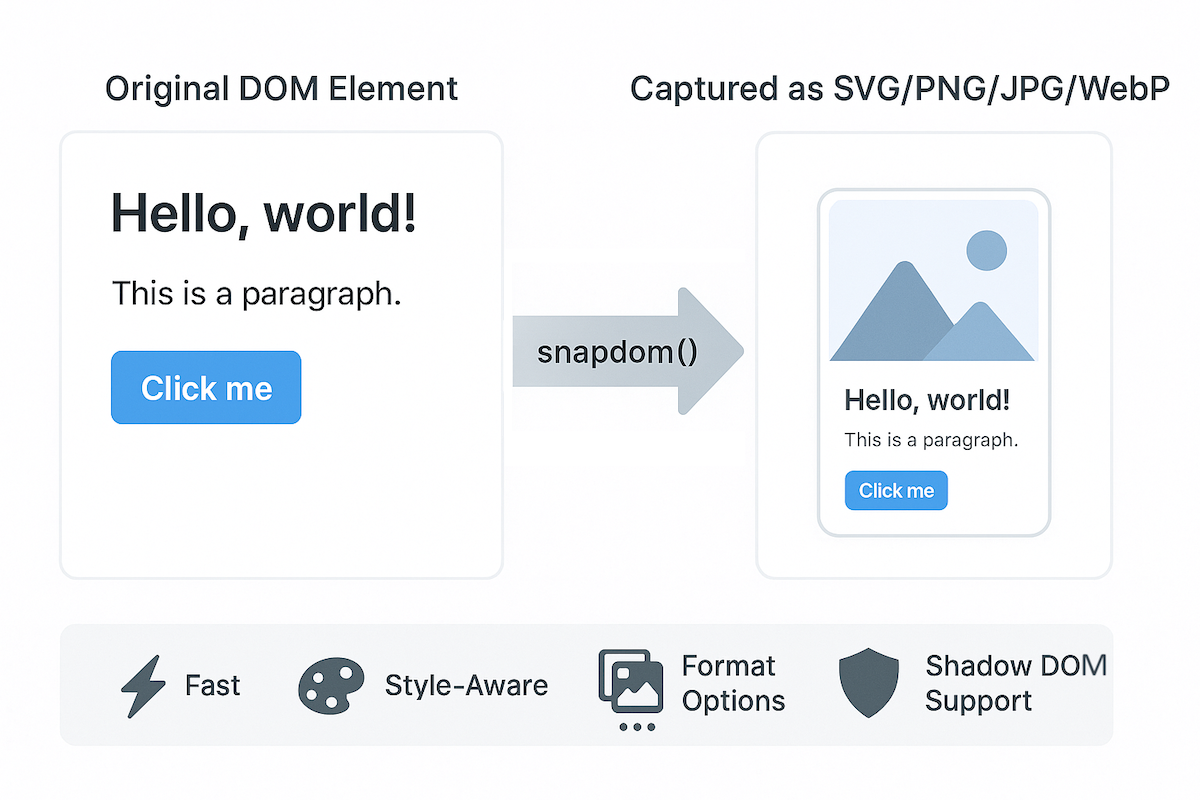
一行代码将网页元素变成图片!比 html2canvas 快 93 倍的截图神器:snapDOM 全解析
2025-07-02 18:27:18 +0800 CST view 3467
Milvus 向量数据库全链路优化:从零构建千亿级向量检索系统的完整实战
2026-05-16 22:47:08 +0800 CST view 440
Redis 8.8 深度解析:全新 Array 数据结构、窗口计数器限流、Streams NACK——性能暴涨 83% 背后的架构革命
2026-06-30 08:43:38 +0800 CST view 222
ClickHouse 26.6 深度实战:当列式存储终于在实时分析赛道碾压一切——从 MergeTree 内核、物化视图管线到千亿级实时数仓的生产级完全指南
2026-07-12 01:42:23 +0800 CST view 172
Vue3中如何进行性能优化?
2024-11-17 22:52:59 +0800 CST view 1518
PHP 高效图像处理库 libvips:内存需求低到离谱,比 Imagick 快 4 倍!
2026-06-11 10:38:04 +0800 CST view 321
PostgreSQL 19 Beta 1 深度实战:212项更新背后的「运维革命」——从AIO自动伸缩到虚拟生成列、从在线校验切换到逻辑复制热激活的生产级完全指南(2026)
2026-06-22 16:25:07 +0800 CST view 338
TypeScript 7.0 深度解剖:为什么微软用 Go 重写编译器,8-12 倍加速背后藏着怎样的工程哲学
2026-07-24 06:43:02 +0800 CST view 60
Vue 3.6 深度解析:Alien Signals 响应式性能暴增 + Vapor 模式颠覆虚拟 DOM
2026-05-11 03:50:22 +0800 CST view 671
PostgreSQL 19 Beta 发布:异步IO自动驾驶与虚拟生成列——数据库运维革命的212项技术变革详解
2026-06-22 16:26:16 +0800 CST view 397