Dify v1.15.0 深度解析:difyctl CLI + 思维链可视化,手把手打造生产级 LLM 应用编排引擎
2026-07-10 18:17:23 +0800 CST view 92
MoneyPrinterTurbo 深度实战:用 AI 大模型一键生成高清短视频——从 LLM 调度策略到批量视频生产的工程化完全指南(2026)
2026-06-02 19:44:20 +0800 CST view 738
AI Hedge Fund 深度解析:当巴菲特遇上大模型——多智能体投资系统的工程革命
2026-04-14 04:53:29 +0800 CST view 1807
用AI做失败复盘:一张提示词,让核心问题自动浮现
2026-04-23 21:28:06 +0800 CST view 514
GraphRAG 知识图谱增强检索实战:从 Leiden 社区检测到生产级部署,一次把图谱 RAG 讲透(2026 深度长文)
2026-07-13 14:18:59 +0800 CST view 41
RAGFlow:81.1k Star开源RAG引擎,AI时代最强外脑
2026-05-26 13:35:41 +0800 CST view 431
LLM推理框架2026选型完全指南:从vLLM到TensorRT-LLM,一次讲透四大引擎的架构哲学与生产级实战
2026-06-02 09:36:52 +0800 CST view 501
Ollama 完全指南:本地大模型部署的事实标准——从原理到生产级 AI 应用开发(2026)
2026-06-05 04:13:34 +0800 CST view 372
Ollama 完全指南:本地大模型部署的事实标准——架构、实战与生产级部署(2026)
2026-06-05 04:13:52 +0800 CST view 419
2026年大模型推理框架横评:vLLM 0.5 vs TGI 2.0 vs TensorRT-LLM 1.8 vs DeepSpeed-MII 0.9
2026-07-10 17:44:16 +0800 CST view 110
LLM推理引擎终极对决:vLLM vs TensorRT-LLM深度解析与2026生产环境选型指南
2026-04-20 13:45:31 +0800 CST view 735
2026大模型推理框架年度横评:vLLM/TGI/TensorRT-LLM/DeepSpeed-MII 架构深度解析与生产级选型指南
2026-06-18 17:54:54 +0800 CST view 479
LLM 推理框架选型实战:vLLM、TensorRT-LLM、TGI、DeepSpeed-MII 深度对比与生产部署指南
2026-07-03 13:49:04 +0800 CST view 220
一套TypeScript代码,编译成macOS/iOS/Android全平台原生应用:Perry开源
2026-04-29 12:17:15 +0800 CST view 1315
Spring AI 1.1 深度解析:从 RAG 到 MCP 协议——Java 开发者构建企业级 AI 应用的工程化实战
2026-05-10 04:41:17 +0800 CST view 540
万字深度解析 LMCache:当 KV Cache 遇见分布式存储革命——从常数级显存到千亿Token并发的完整技术指南(2026)
2026-07-02 13:46:08 +0800 CST view 188
LMCache 深度拆解:当 KV Cache 变成可复用资产——LLM 推理的「免费午餐」完整指南
2026-07-14 18:47:11 +0800 CST view 16
使用NativePHP构建高效的桌面应用程序,运行于Laravel框架
2024-11-18 08:05:35 +0800 CST view 1591
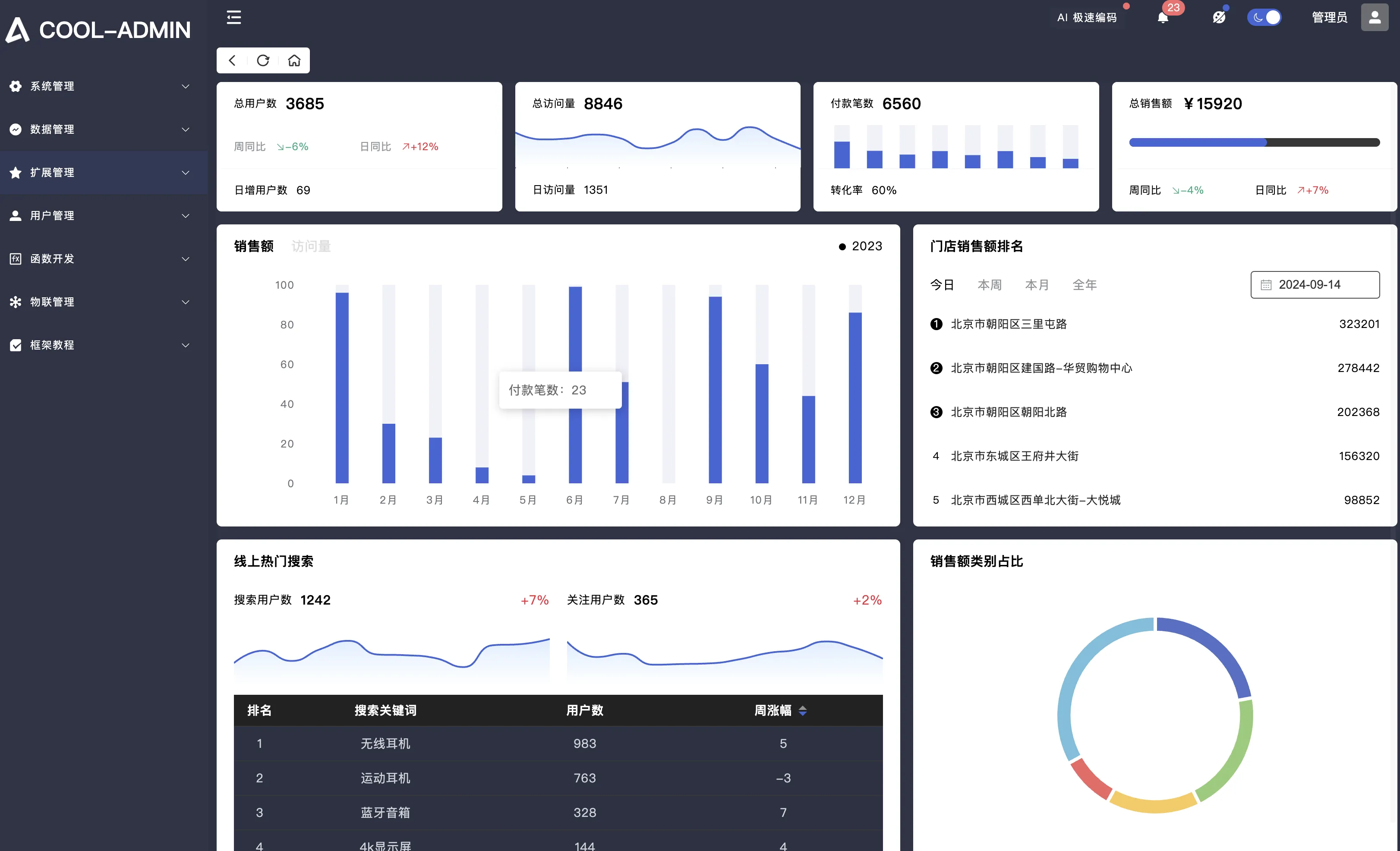
中后台开发神器!Cool-Admin-Midway 让你一分钟完成后台搭建!
2024-11-18 01:31:19 +0800 CST view 2318
一个轻量级、零依赖的JavaScript模糊搜索库,适用于前端和后端应用
2025-05-05 19:31:53 +0800 CST view 1691
Vue3 中引入的 Vue Router 4 与 Vue Router 3 有哪些不同之处?
2024-11-19 01:06:37 +0800 CST view 1607