10 万条数据毫秒级前端模糊搜索方案
在下拉选择框、数据表格或搜索栏中,用户往往期望实时看到搜索结果。
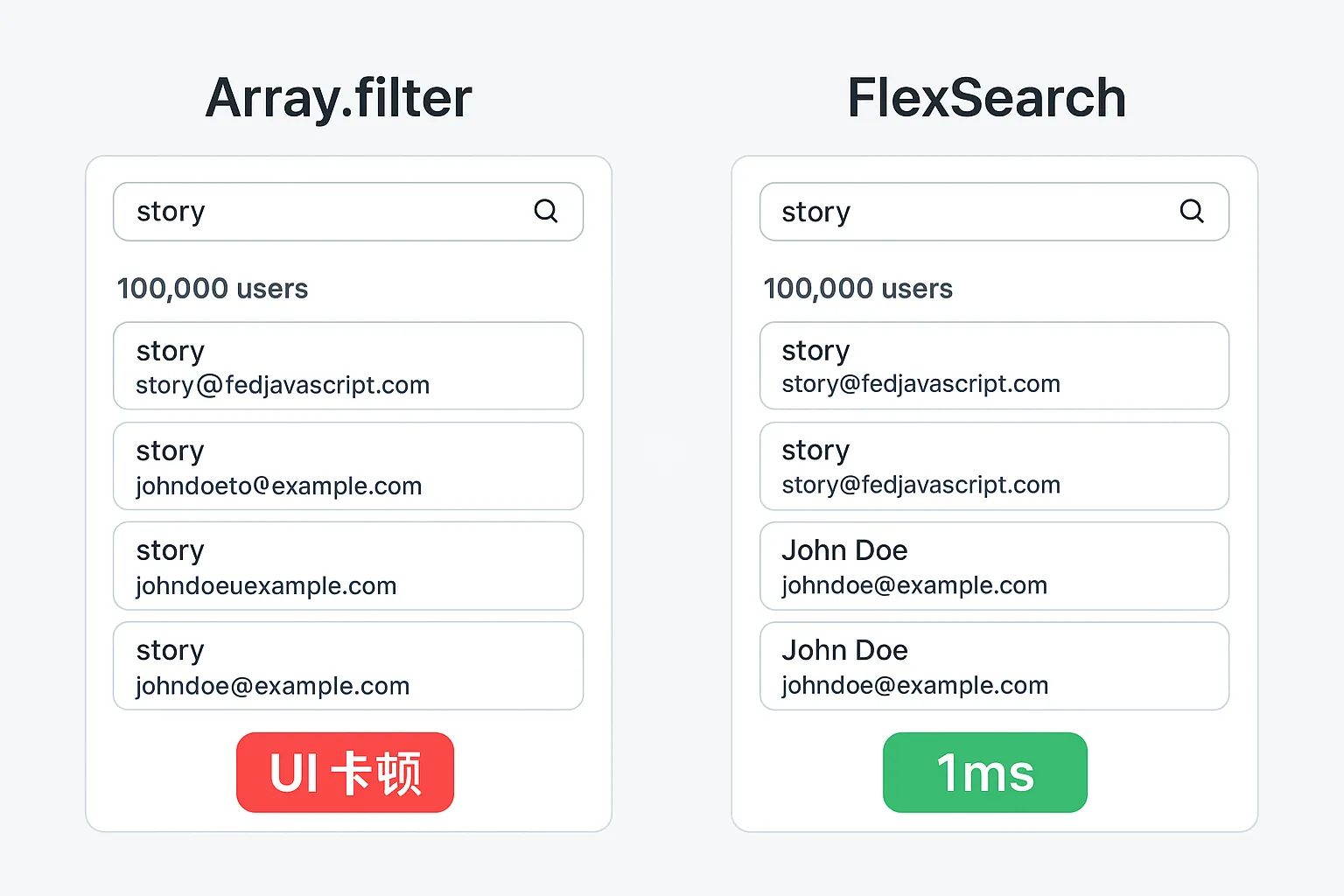
然而,当数据量达到 10 万级时,传统的前端搜索方法(例如 Array.filter)会造成UI 卡顿甚至浏览器崩溃。
本文将带你用 FlexSearch.js 实现毫秒级模糊搜索,并给出性能优化的最佳实践。
1. 为什么传统搜索会卡死页面?
假设有 10 万条用户数据:
const allUsers = [
{ id: 1, name: "story", email: "story@fedjavascript.com" },
// ... 99999 more users
];
const query = 'userNameOrEmail';
// 传统过滤
const results = allUsers.filter(user =>
user.name.toLowerCase().includes(query) ||
user.email.toLowerCase().includes(query)
);
问题:
filter每次输入都会遍历所有数据 → O(n) 复杂度- 大数据量下会占用主线程 → UI 阻塞
- 高频输入(例如快速打字)会触发多次全量遍历 → 卡顿加剧
2. 核心优化思路:预计算 + 索引
性能优化的核心思路是:
用空间换时间,在数据加载时构建索引,查询时直接命中索引,而不是每次都全量扫描。
自己实现高效索引结构(如 Trie 树、倒排索引)较为复杂,幸运的是,社区已有成熟方案——FlexSearch.js。
3. 使用 FlexSearch 重构
安装
npm install flexsearch
构建索引
import FlexSearch from 'flexsearch';
// 创建索引(开启 Web Worker)
const index = new FlexSearch.Document({
document: {
id: 'id',
index: ['name', 'email'] // 要搜索的字段
},
worker: true, // 开启多线程
tokenize: 'forward', // 分词策略(提升前缀匹配速度)
encode: 'icase' // 忽略大小写
});
// 一次性构建索引(可能耗时几百毫秒~几秒)
allUsers.forEach(user => index.add(user));
毫秒级搜索
const query = 'story';
const results = index.search(query, { limit: 100 });
// 如果需要拿到完整数据
const matchedUsers = results.flatMap(res => res.result)
.map(id => allUsers.find(u => u.id === id));
由于使用了预构建索引,即使在 10 万条数据中,搜索也能稳定在 1ms 左右。
4. Web Worker 加速
即使索引构建和搜索都很快,大数据处理仍然会占用主线程,影响 UI 流畅度。
最佳实践是——把 FlexSearch 运行在 Web Worker 中。
// worker.js
import FlexSearch from 'flexsearch';
const index = new FlexSearch.Document({ /* 配置 */ });
self.onmessage = ({ data }) => {
if (data.type === 'add') {
data.payload.forEach(doc => index.add(doc));
}
if (data.type === 'search') {
const results = index.search(data.query, { limit: data.limit || 100 });
self.postMessage(results);
}
};
在主线程:
const worker = new Worker('worker.js');
worker.postMessage({ type: 'add', payload: allUsers });
worker.postMessage({ type: 'search', query: 'story', limit: 50 });
worker.onmessage = (e) => {
console.log('搜索结果', e.data);
};
5. 搜索体验优化
防抖(Debounce)
防止用户每敲一个字就触发搜索:
function debounce(fn, delay) {
let timer;
return (...args) => {
clearTimeout(timer);
timer = setTimeout(() => fn.apply(this, args), delay);
};
}
const searchHandler = debounce((query) => {
worker.postMessage({ type: 'search', query });
}, 200);
预加载索引
- 在应用初始化时加载数据并构建索引
- 可在后台悄悄完成(例如用户打开首页时)
限制返回条数
- 建议限制为 前 50 ~ 200 条,避免一次性渲染过多 DOM 节点
- 对数据表格可配合 虚拟滚动 进一步优化渲染性能
6. 总结
| 方法 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|
Array.filter | 慢(O(n)) | 简单 | 小数据量 |
| 自实现索引结构 | 中 | 高 | 定制化需求 |
| FlexSearch.js | 毫秒级 | 低 | 大数据量模糊搜索 |
最佳实践:
- 数据初始化时构建索引
- 搜索逻辑放到 Web Worker
- 输入事件加防抖
- 限制搜索结果条数
- 结合虚拟滚动优化渲染
💡 一句话总结
传统
Array.filter在 10 万条数据面前是“乌龟”,而 FlexSearch.js + Web Worker 可以让你在毫秒内“闪现”搜索结果。