FishSpeech是一个全新的文本到语音(TTS)解决方案,采用变分自编码器、声码器和生成对抗网络等先进技术,提供高质量、自然的语音合成
Fish Speech 简介
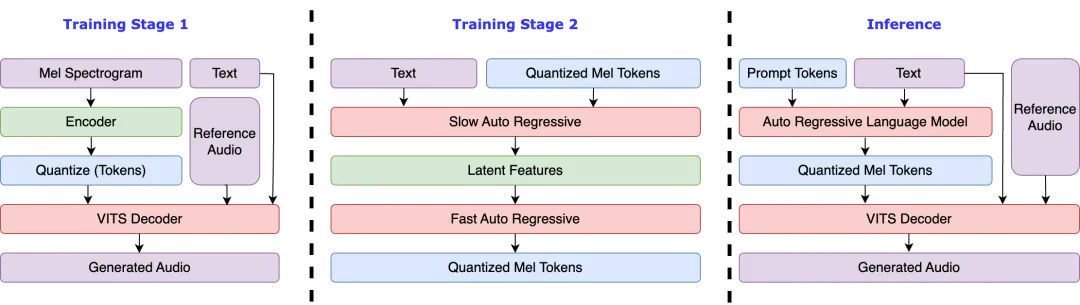
Fish Speech 是一个全新的文本到语音(TTS)解决方案,致力于提供高效、自然的语音合成体验。该项目采用了最先进的技术,如变分自编码器(VAE)、声码器(Vocoder)和生成对抗网络(GAN),生成高质量的语音输出。
项目特点
主要特点
- 高质量语音合成:利用最新的深度学习技术,生成接近真人的语音合成效果。
- 多种语言支持:支持包括英语、中文、日语在内的多种语言。
- 开源代码:项目全部开源,方便开发者进行二次开发和定制。
- 易于部署:提供详细的部署指南和文档,帮助用户快速上手。
使用场景
- 虚拟助手:为智能设备提供自然语言交互的语音输出。
- 有声读物:自动将文本转换为有声读物,方便视力受限的用户使用。
- 客户服务:在客户服务系统中提供自动语音回复功能。
- 教育工具:辅助语言学习,提供标准的发音示范。
项目使用
环境要求
- GPU 内存: 4GB(用于推理),8GB(用于微调)
- 系统: Linux, Windows
快速使用
- 快速开始:通过运行
inference.ipynb进行本地推理,体验 Fish Speech 的语音合成效果。 - 在线演示:提供在线演示,用户可直接在网页上尝试语音合成功能。
- 文档阅读:详细的多语言文档帮助用户了解项目的使用方法和配置。
- 视频教程:通过 V1.4 演示视频,用户可以更直观地了解项目功能和操作流程。
参考文档
- 中文文档:Fish Speech 中文文档
- 在线演示:Fish Speech 在线演示
注:本文内容仅供参考,具体项目特性请参照官方 GitHub 页面的最新说明。
欢迎关注、点赞和在看,感谢你的支持与阅读!