Llama 3.1 Omni:颠覆性的文本与语音双输出模型
你可能听说过不少关于语言模型的进展,但如果告诉你,有一种模型不仅能生成文本,还能同时生成语音,你会不会觉得特别酷?今天我们就来聊聊一个相当前沿的项目——Llama 3.1 Omni模型。这个模型打破了传统的文字生成边界,实现了文本与语音的双重输出,真正让“多模态”(multi-modal)能力成为现实。
喜欢直接读论文的朋友可以参考这里:
https://arxiv.org/pdf/2409.06666
1. Llama 3.1 Omni是什么?
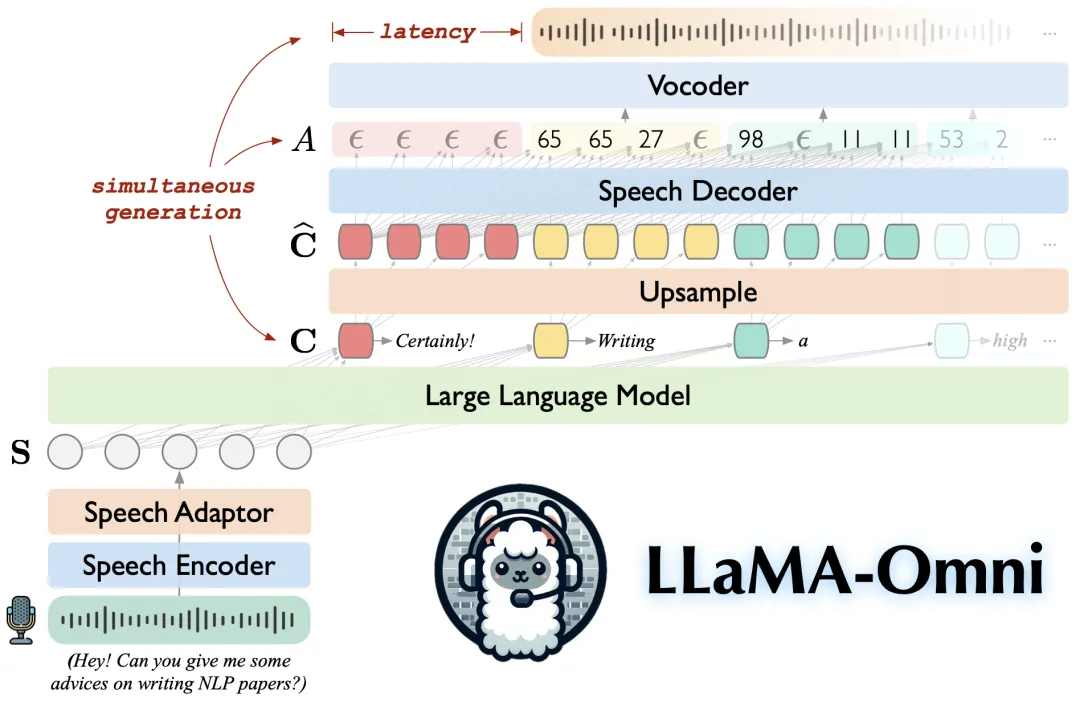
Llama 3.1 Omni模型,顾名思义,基于Llama 3.1的框架开发。它的独特之处在于能够同时生成文本和语音。简单来说,不仅可以通过模型获取文字内容,还能直接听到相应的语音输出。想象一下,一个可以自动朗读并带有情感表达的模型,无论是科研人员还是开发者,都会觉得这种功能极具吸引力。
Llama 3.1 Omni非常适合那些需要文字与语音同时输出的场景。举个例子,当你在开发一个聊天机器人时,用户不但能看到回复的文字,还能直接听到语音版本。这种双输出大大提升了用户体验。
2. Llama 3.1 Omni与其他模型的区别
与其他语言模型相比,Llama 3.1 Omni在多模态输出上具有显著优势。与OpenAI的GPT-4等模型主要专注于文本生成不同,Llama 3.1 Omni特别适合需要语音互动的场景,尤其是本地化部署时的应用需求。
此外,它的架构基于Llama 3.1-8B-Instruct,这意味着它是一个规模庞大、训练精度高的模型,具备极强的指令跟随能力。通过简单的指令,你不仅能获得精准的文本回复,还能听到相应的语音,这在很多任务中能够大幅简化工作流程。
3. 应用场景:为什么你应该关心?
Llama 3.1 Omni可以在多个实际场景中大放异彩:
客户服务:在自动化客户服务领域,Llama 3.1 Omni的语音功能使得聊天机器人更加拟人化,提升了用户的互动体验和满意度。
教育行业:教师可以使用Llama 3.1 Omni为学生实时朗读生成的内容,提供更具互动性的学习体验,尤其适用于双语教学场景。
医疗健康:患者通过与模型对话,能够获得语音反馈,提升了远程医疗的便利性,特别适合视障或行动不便的患者。
这些只是Llama 3.1 Omni应用的冰山一角,随着时间推移,它在多模态交互领域的应用必将更加广泛。
4. Llama 3.1 Omni的实际性能如何?
在性能方面,Llama 3.1 Omni不仅能生成流畅的文本,语音输出也极其自然,具有较高的可理解性,不会像一些生硬的语音生成模型那样缺乏情感表达。技术上,Llama 3.1 Omni使用了8B参数量的模型,这使其拥有强大的推理能力和生成质量。
更值得注意的是,Llama 3.1 Omni是开源的,开发者可以根据具体需求对其进行定制,甚至本地化运行,以确保数据隐私。
5. 如何开始使用Llama 3.1 Omni?
你可能会担心这样一个强大的模型使用门槛会不会很高?其实完全不用担心。Llama 3.1 Omni的使用非常简单,开源社区提供了详细的安装步骤,开发者只需在GitHub仓库下载模型,按照说明文档操作即可。
git clone https://github.com/ictnlp/LLaMA-Omni
cd LLaMA-Omni
conda create -n llama-omni python=3.10
conda activate llama-omni
pip install pip==24.0
pip install -e .
python -m omni_speech.serve.gradio_web_server --controller http://localhost:10000 --port 8000 --model-list-mode reload --vocoder vocoder/g_00500000 --vocoder-cfg vocoder/config.json
它可以轻松集成到现有的AI应用中,无需从头开发,这对项目开发者来说无疑是巨大的便利。
抓住机会,赶紧上车
Llama 3.1 Omni模型的出现无疑让AI应用朝着更智能和多样化的方向迈进了一大步。无论是为了提升用户体验,还是进行更高效的多模态互动,这个模型都提供了极具价值的工具。尤其在AI日益融入各行业的今天,掌握并利用这样的工具,将极大提升你的工作效率和竞争力。
所以,如果你从事的是需要文字、语音互动的领域,千万不要错过Llama 3.1 Omni这个宝贵的机会!