VibeVoice 深度解析:微软 45K Star 开源语音 AI,重新定义长音频处理范式
2026-04-29 11:11:12 +0800 CST view 344
VibeVoice 深度解析:微软开源语音AI全家桶——从7.5Hz超低帧率到Next-Token Diffusion的技术革命
2026-05-17 18:16:11 +0800 CST view 326
Insanely Fast Whisper 深度解析:比原版快 10 倍的语音转文字引擎——从原理到生产级部署的完整实战
2026-04-29 16:24:38 +0800 CST view 368
Vosk-API 是一款开源的离线语音识别工具包
2024-11-19 07:51:49 +0800 CST view 3794
零成本在本地跑 Whisper:从视频自动生成双语字幕
2026-06-08 15:48:58 +0800 CST view 257
Pynini是一个开源的Python库,专注于构建语言模型和处理字符串
2024-11-19 04:26:54 +0800 CST view 3606
NVIDIA PersonaPlex 全双工语音 AI 深度解析:从 Moshi 架构到实时对话的工程实践
2026-04-19 14:16:23 +0800 CST view 632
VibeVoice 深度实战:当微软用 60 分钟长音频打破语音 AI 的「时长诅咒」——从实时语音合成到 Hugging Face 生态集成的生产级完全指南(2026)
2026-06-17 00:25:12 +0800 CST view 170
VoxCPM2 深度实战:当开源 TTS 突破「tokenizer 诅咒」——从Tokenizer-Free 架构到本地 CPU/GPU 部署的完全指南(2026)
2026-06-09 14:50:53 +0800 CST view 217
OmniVoice 深度实战:当小米 AI 实验室把 600 种语言的 TTS 引擎彻底开源——从零样本语音克隆到单阶段 NAR 架构的生产级完全指南(2026)
2026-06-11 11:18:37 +0800 CST view 291
VibeVoice 深度实战:从 7.5Hz 超低帧率到 Next-token Diffusion——2026 年微软开源语音 AI 模型家族的架构完全指南
2026-05-23 22:32:58 +0800 CST view 309
MOSS-TTS-Nano:0.1B参数纯CPU实时语音生成与克隆,MacBook Air单核就能跑
2026-04-20 22:53:28 +0800 CST view 1043
VibeVoice 深度解析:微软开源语音 AI 全家桶,90 分钟长语音合成 + 60 分钟语音识别
2026-05-13 22:42:48 +0800 CST view 394
VibeVoice 深度实战:微软开源的 33K Star 语音AI全家桶——从架构设计到生产部署的全链路解析
2026-05-06 13:01:56 +0800 CST view 813
VibeVoice 深度解析:微软如何用 7.5Hz 连续语音分词器重新定义语音 AI 的边界
2026-04-18 07:48:59 +0800 CST view 403
VibeVoice 深度实战:当 TTS 遇见扩散模型与 LLM——从 3200 倍压缩到 90 分钟多人对话的生产级完全指南(2026)
2026-06-16 02:16:25 +0800 CST view 206
PHP中集成腾讯云人脸识别服务,并将结果写入数据库
2024-11-18 23:24:17 +0800 CST view 1598
WiFi 信号穿墙感知与人体姿态识别:从 CSI 到 DensePose 的工程化完全指南(2026)
2026-05-25 01:21:49 +0800 CST view 397
WiFi-DensePose 深度实战:用普通路由器实现穿墙人体姿态识别——2026年完全指南
2026-05-25 05:52:18 +0800 CST view 438
如何使用PHP操作摄像头进行情感识别,通过表情解析分析人的情绪
2024-11-18 11:32:03 +0800 CST view 1680
Vue 如何识别图片中的文字,并把这些文字转化成文本
2024-11-19 10:07:00 +0800 CST view 1706
百度 Unlimited OCR 深度解读:R-SWA 如何将 KV Cache 压成常数,5天 GitHub Star 破万的端到端 OCR 新范式
2026-06-27 09:15:20 +0800 CST view 49
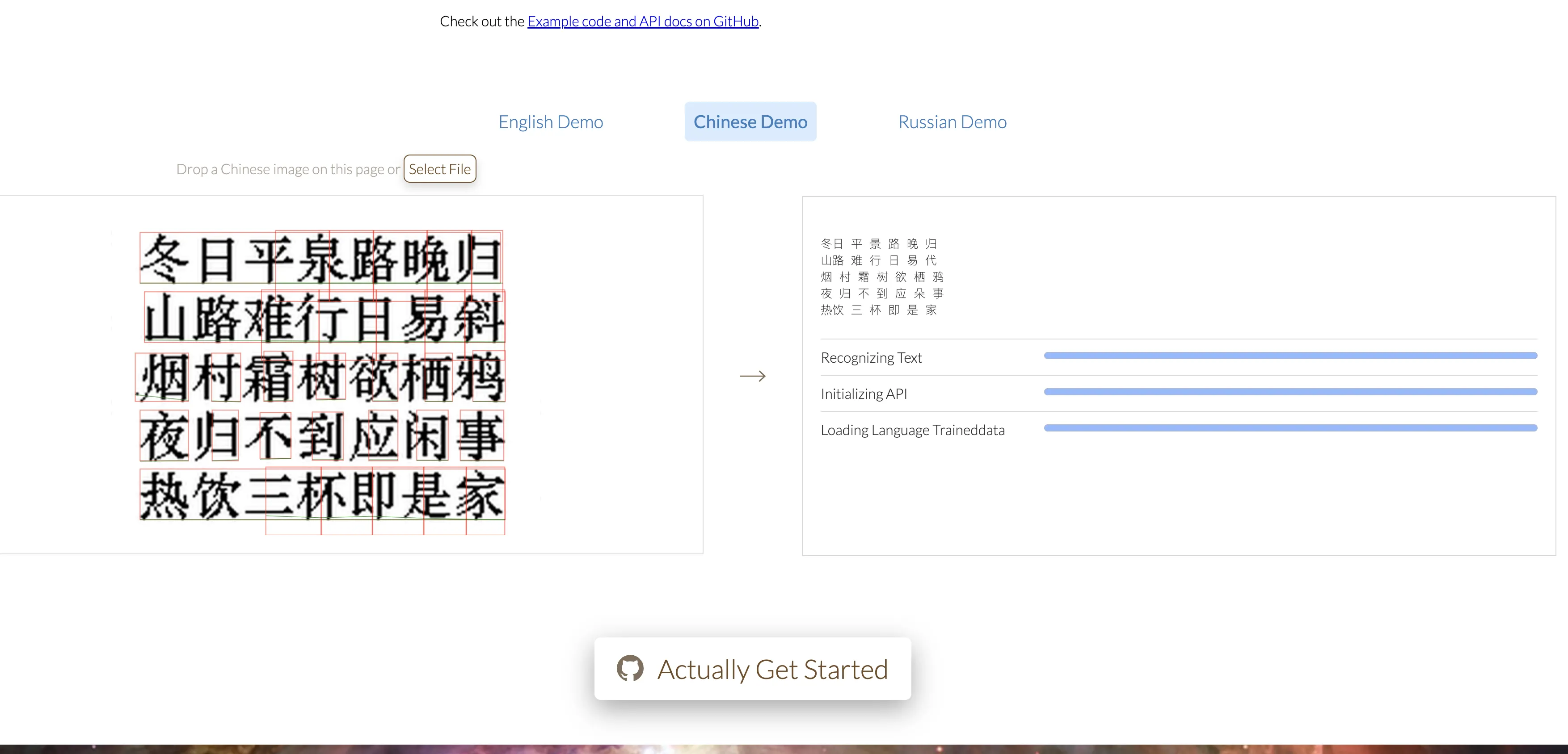
34.4K Star 最牛 OCR !!! 不要服务器, 浏览器识别 100+ 语言文本
2024-11-19 07:16:38 +0800 CST view 2264
百度 Unlimited OCR 深度解析:R-SWA 如何让长文档 OCR 从"逐页煎熬"走向"一次搞定"
2026-06-28 14:13:06 +0800 CST view 50